
Zhiqiang He 何志强
Ph.D. Researcher at the University of Electro-Communications, Tokyo, working on reinforcement learning. Previously an RL engineer at InspirAI and a research intern at Baidu.
Experience
-
2022 — 2023
RL Algorithms EngineerTop Performance Team
InspirAI, Hangzhou
Built a card-game AI SDK shipped across four production titles; the Landlord agent reached super-human level against top-ranked professional players. A similar (independently developed) approach also powered a Guandan agent, improving its win rate by 6%.

Dou Dizhu (Landlord) — the flagship title shipping the card-game AI 
Guandan AI — four agents in a live match (a similar RL approach) -
2021
RL Research InternSuper Special Offer
Baidu, Beijing
Single-handedly developed EDA-MAPPO — the full algorithm and its performance gains — and shipped it into a client production environment.
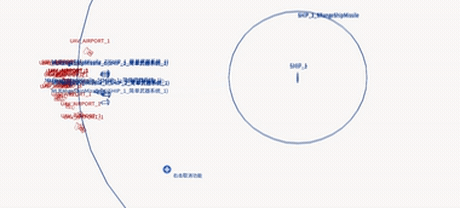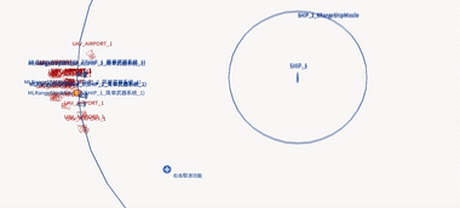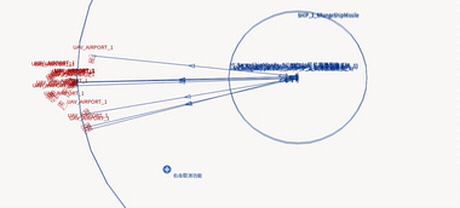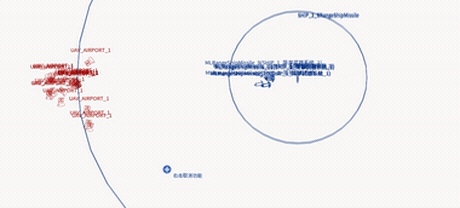
Deployed system — UAV swarm engaging a naval target (EDA-MAPPO) 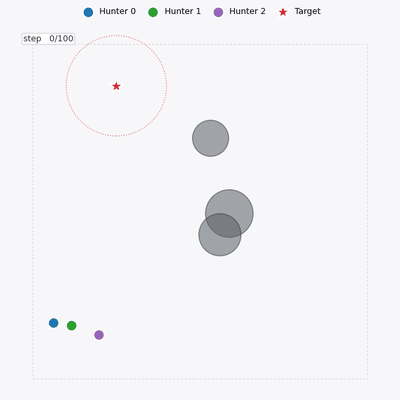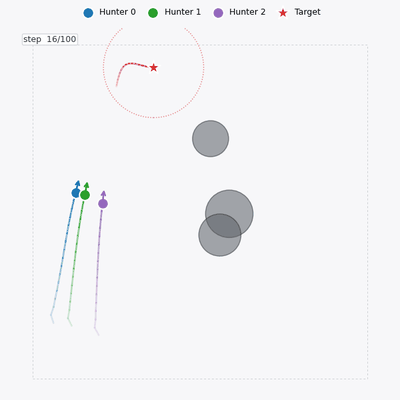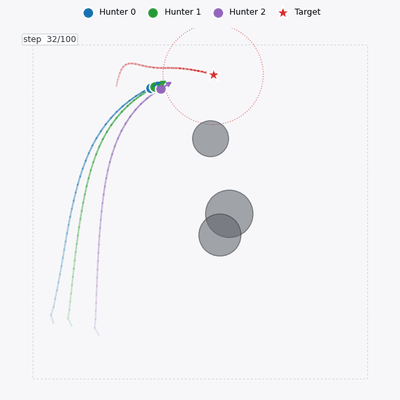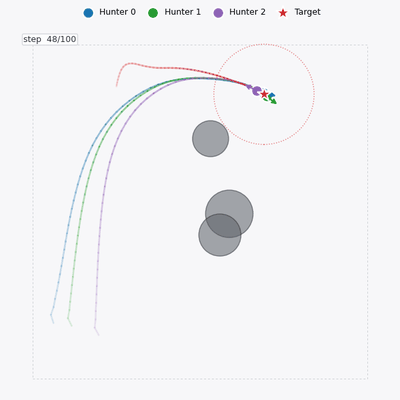
light_mappo — open-source prototype (multi-agent PPO)
Education
- 2024 — Ph.D. in Information Science · University of Electro-Communications, Tokyo · Prof. Zhi Liu
- 2019 — 2022 M.S. in Control Science and Engineering · Northeastern University, Shenyang · Prof. Jiao Wang
- 2015 — 2019 B.S. in Automation · East China Jiaotong University, Nanchang
Awards
- 2025–2027 Selected as a JST Next-Generation Researcher (¥2.2M/year stipend plus ¥600K/year research funding).
- 2019 Selected as Outstanding Graduate (Top 1%) at East China Jiaotong University.
Service
Peer reviewer for
- ACM International Conference on Multimedia (ACM MM 2026)
- IEEE Transactions on Multimedia
- IEEE Transactions on Network Science and Engineering
- IEEE Internet of Things Journal
- IEEE Open Journal of the Computer Society Certificate
Conference volunteer
- Student Volunteer, IEEE INFOCOM 2026, Tokyo Certificate
Publications
-
NSMA: Neuro-Symbolic Manifold Alignment for Generalizable Adaptive Bitrate Streaming under Texture Shift
Zhiqiang He, Zhi Liu
arXiv preprint, 2026Preprint
-
Plasticity-Aware Mixture of Experts for Learning Under QoE Shifts in Adaptive Video Streaming
Zhiqiang He, Zhi Liu
IEEE Transactions on Multimedia, 2026 · IF 9.7 · JCR Q1 · CCF-AAccepted
-
Silent Neuron Theory and Plasticity Preservation for Deep Reinforcement Learning in Adaptive Video Streaming
Zhiqiang He, Zhi Liu
arXiv preprint, 2025Preprint
-
A Survey on DRL based UAV Communications and Networking: DRL Fundamentals, Applications and Implementations
Wei Zhao, Shaoxin Cui, Wen Qiu*, Zhiqiang He*, Zhi Liu, Xiao Zheng, Bomin Mao, Nei Kato
IEEE Communications Surveys & Tutorials, 2025 · IF 42.8 · JCR Q1
-
Understanding World Models through Multi-Step Pruning Policy via Reinforcement Learning
Zhiqiang He, Wen Qiu, Wei Zhao, Xun Shao, Zhi Liu
Information Sciences, 2024 · IF 8.1 · JCR Q1
-
DiPerceiveNet: A bidirectional cross-scale perception network for vehicle re-identification
Jihao Cai, Zhiqiang He, Zhi Liu, Yangjie Cao
Pattern Recognition, 2026 · IF 7.6 · JCR Q1
-
Plasticity-Enhanced Multi-Agent Mixture of Experts for Dynamic Objective Adaptation in UAV-Assisted Emergency Communication Networks
Wen Qiu, Zhiqiang He, Wei Zhao, Hiroshi Masui
IEEE Internet of Things Journal, 2026 · IF 8.7 · JCR Q1Accepted