Abstract
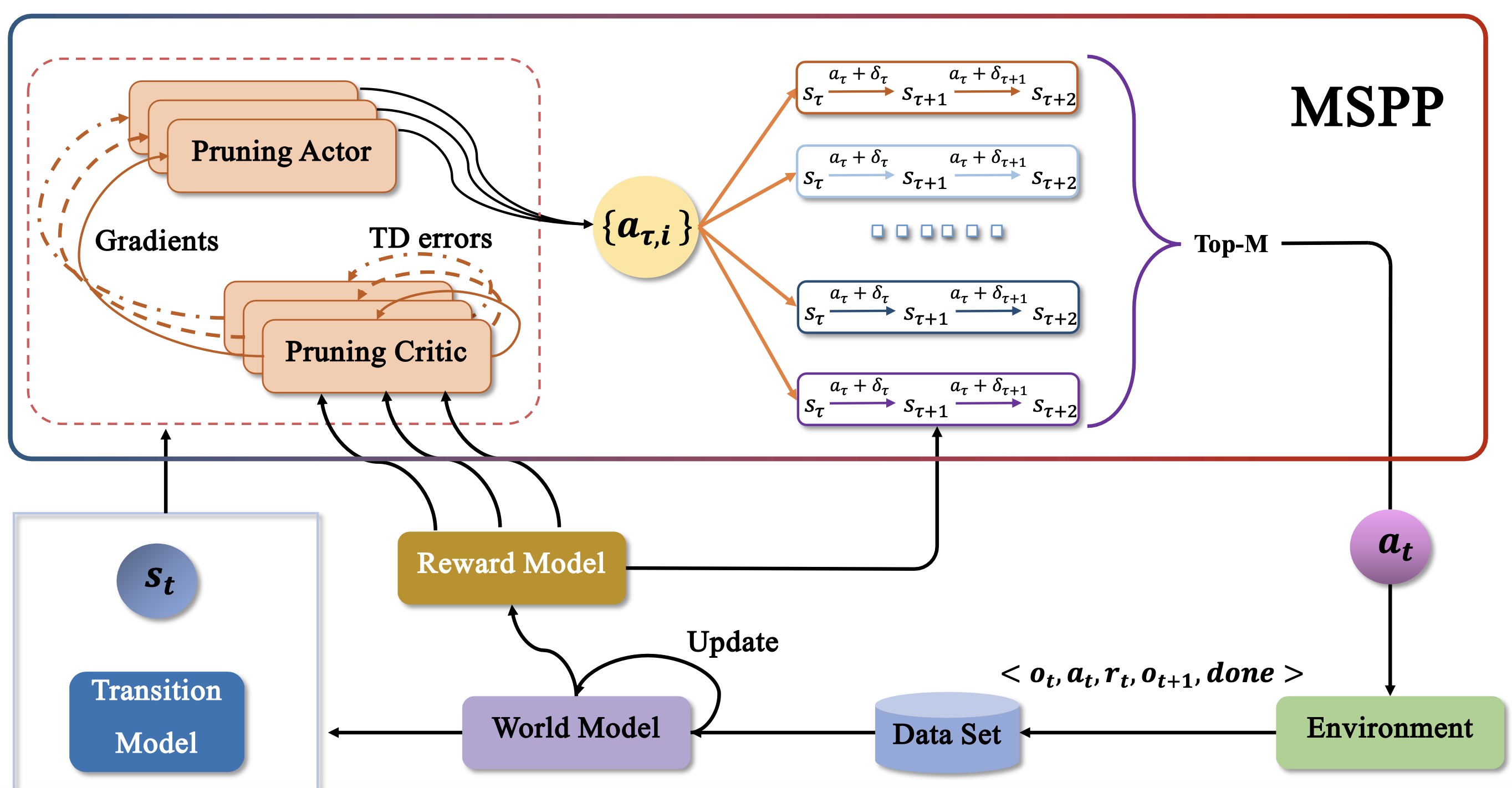
Parallel multi-step pruning policies enhance diversity sampling, with convergence analysis for MSPP and a corresponding policy gradient theorem.
Parallel multi-step pruning policies enhance diversity sampling for world-model based RL, backed by a convergence analysis and a policy gradient theorem.