|
Zhiqiang He (何志强) I am a Ph.D. student at the University of Electro-Communications (UEC), Tokyo, advised by Prof. Zhi Liu. My research focuses on reinforcement learning and its applications across real-world decision-making problems. Previously, I earned an M.S. from Northeastern University under the supervision of Prof. Jiao Wang. I interned as a Research Engineer at Baidu Beijing from June to September 2021 (Received Super Special Offer), followed by a role as a Reinforcement Learning Algorithms Engineer at InspirAI from June 2022 to May 2023 (Received Top-Performing Team Prize). Email / CV / Google Scholar / Github / Zhihu / |

|
Academic Activities & AwardsServed as a peer reviewer for IEEE Transactions on Network Science and Engineering; IEEE Internet of Things Journal; IEEE Open Journal of the Computer Society. Awards: JST (Japan Science and Technology Agency) Next-Generation Researcher (2.2 million yen per year, 2025) ; Outstanding Graduate (Top 1%, 2019) ; |
Publication / Preprint |
|
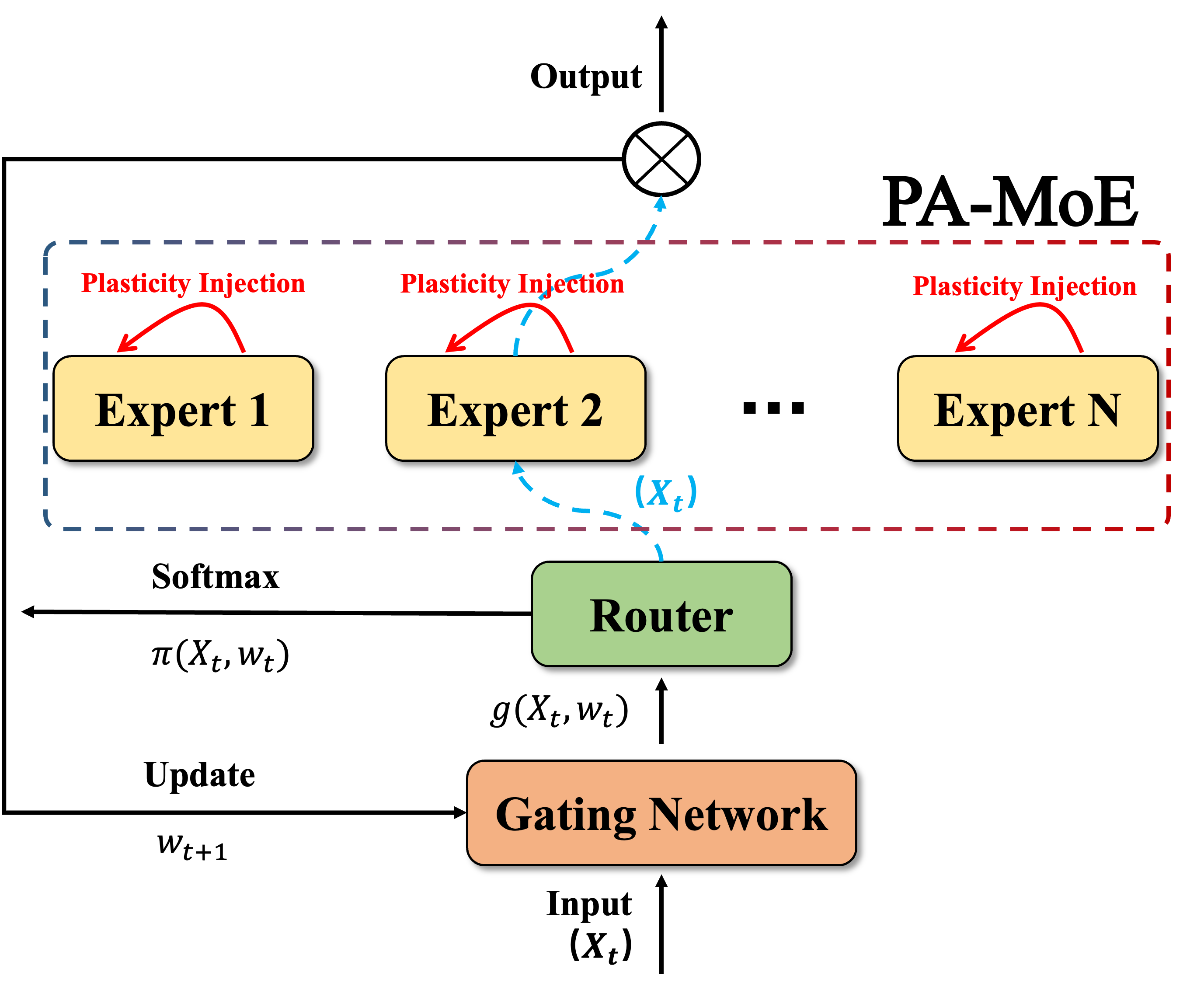
Plasticity-Aware Mixture of Experts for Learning Under QoE Shifts in Adaptive Video Streaming Zhiqiang He, Zhi Liu, IEEE Transactions on Multimedia (Accepted) , 2025. (IF=9.7, Q1) Source Code | Download PDF | Response 1 PDF | Response 2 PDF Mitigate plasticity loss in mixture-of-experts under shifting objectives, with theoretical justification. |
|
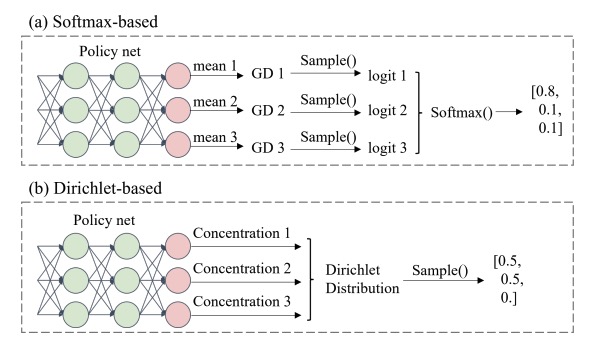
Scalable and Reliable Multi-agent Reinforcement Learning for Traffic Assignment Leizhen Wang, Peibo Duan, Cheng Lyu, Zewen Wang, Zhiqiang He, Nan Zheng, Zhenliang Ma Communications in Transportation Research, 2025. (IF=14.5, Q1) Source Code | Download PDF A scalable multi-agent approach focusing on the action space policy. |
|
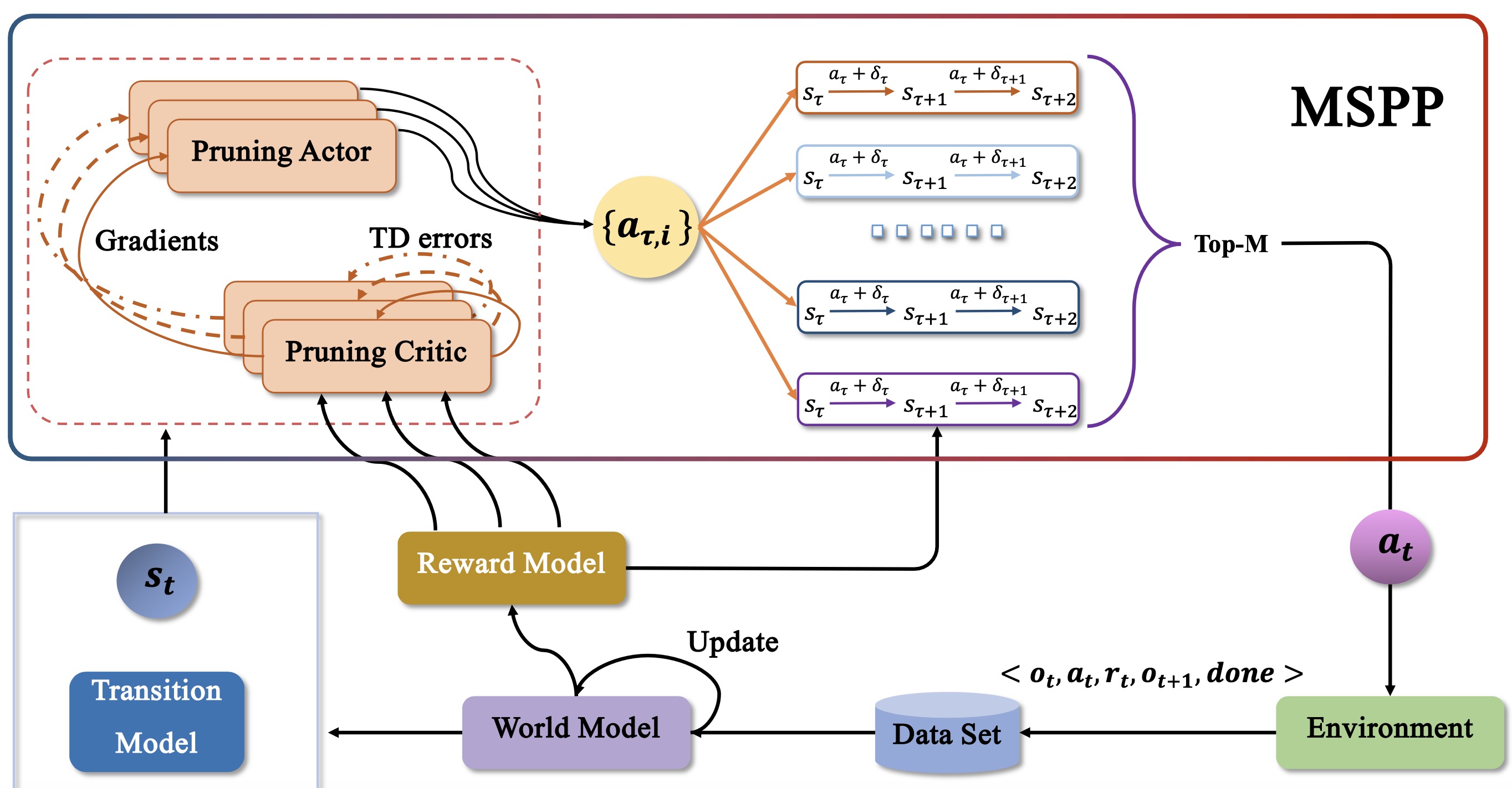
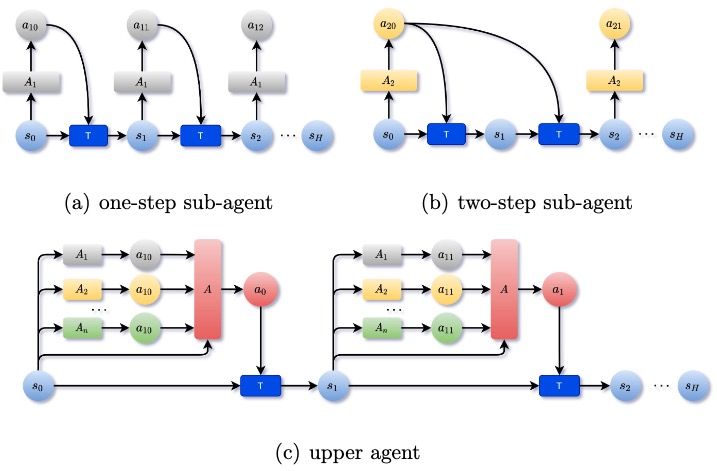
Understanding World Models through Multi-Step Pruning Policy via Reinforcement Learning Zhiqiang He, Wen Qiu, Wei Zhao, Xun Shao, Zhi Liu Information Sciences, 2025. (IF=8.1, Q1) Source Code | Download PDF Parallel Multi-Step Pruning Policies enhance diversity Sampling. (Analysis of convergence theory for MSPP and its PG Theorem.) |
|
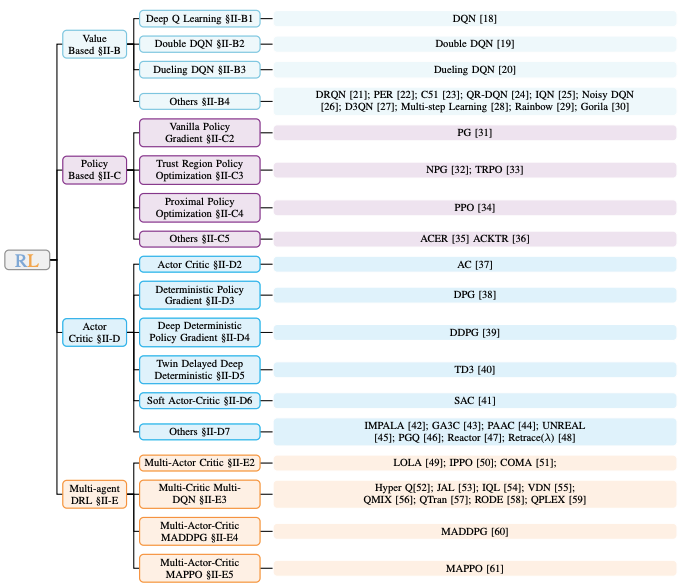
A Survey on DRL based UAV Communications and Networking: DRL Fundamentals, Applications and Implementations Wei Zhao, Shaoxin Cui, Wen Qiu*, Zhiqiang He*, Zhi Liu, Xiao Zheng, Bomin Mao, Nei Kato IEEE Communications Surveys & Tutorials, 2025. (IF=42.8, Q1), * Corresponding author This survey outlines the evolution of fundamental reinforcement learning theory, highlighting how core challenges have driven the development of new methods. |
|
Erlang planning network: An iterative model-based reinforcement learning with multi-perspective Jiao Wang, Lemin Zhang, Zhiqiang He, Can Zhu, Zihui Zhao Pattern Recognition, 2022. (IF=8.5, Q1) Source Code | Download PDF Bi-level reinforcement learning in Model-Based Reinforcement Learning. |
|
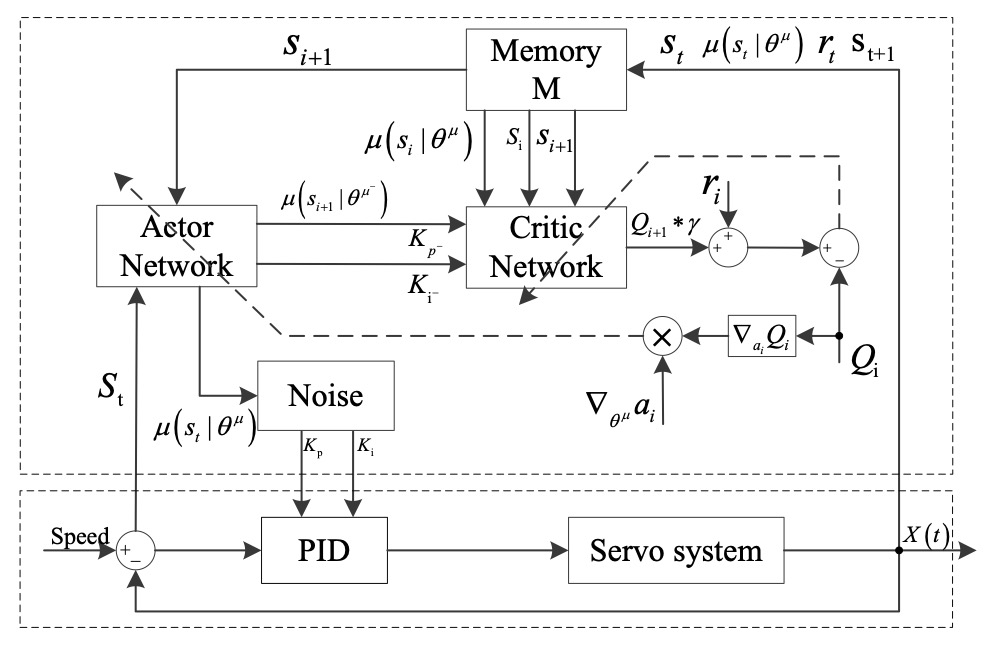
Control Strategy of Speed Servo Systems Based on Deep Reinforcement Learning Pengzhan Chen, Zhiqiang He, Chuanxi Chen, Jiahong Xu Algorithms, 2018 Source Code | Download PDF (Cited 58 times) First paper applied Reinforcement Learning in Jump Speed Servo System. |
|
Thanks Jon Barron for his website template. |